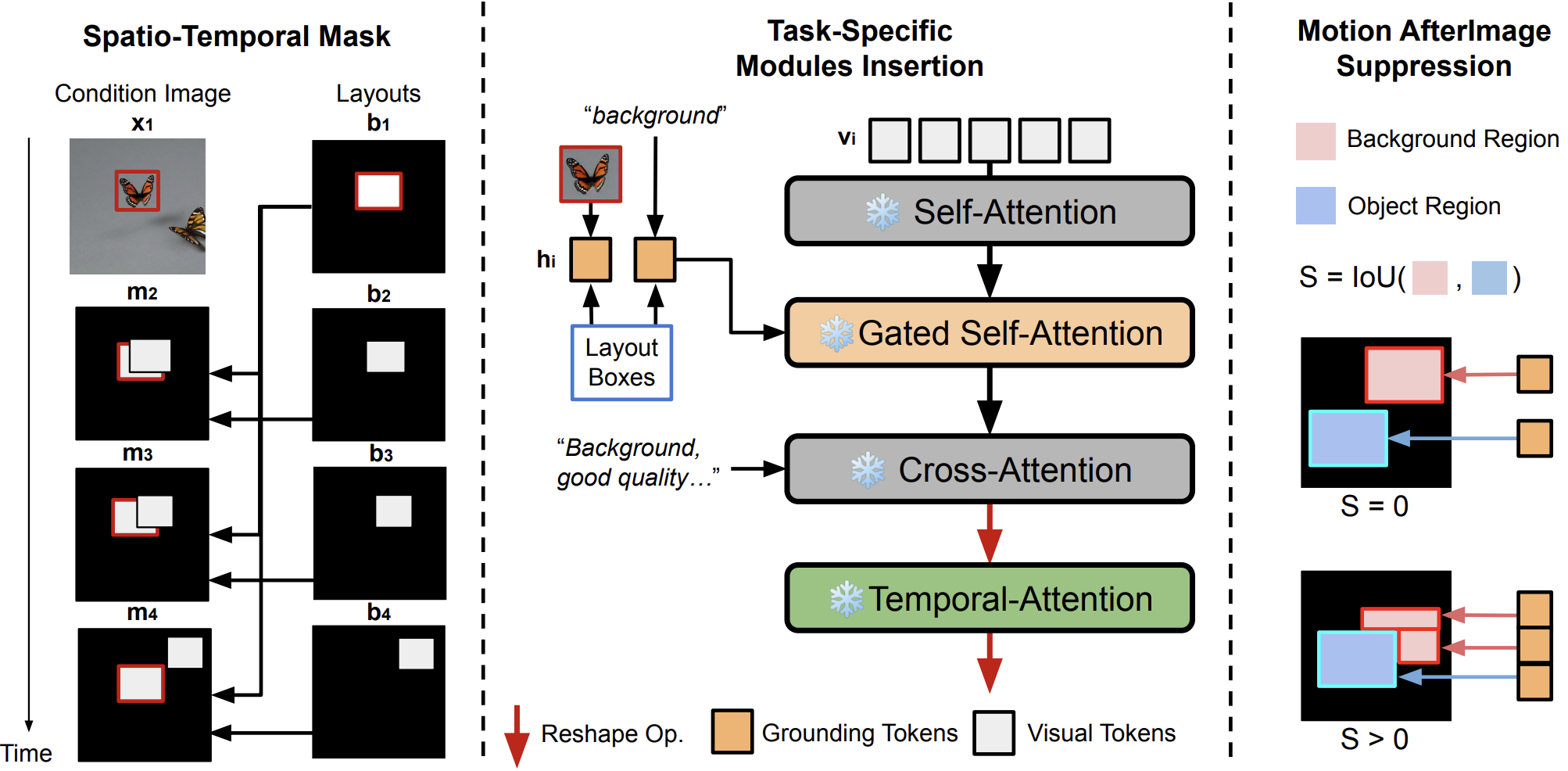
I am a member of technical staff in Microsoft AI's Super Intelligence Team, focusing on visual generation and multi-modal learning. My recent focus includes controllable video generation, large scale training for diffusion models, and representation learning.
News
[2026 June] - MAI-Image-2.5 released. Top-2 Image generation model on LMArena.
[2026 March] - Joined Microsoft AI's Super Intelligence Team.
[2025 Sep] - New video generation model (Seedance-1.0-mini - TikTok production model) trained by us is online. Check out its first effect - AI Flower (2M+ posts on TikTok in one week). AI Mermaid Effect is online, more than 35M post on TikTok - best TikTok Global AI effect since 2023!
@article{fang2025magref,
title={MAGREF: Masked Guidance for Any-Reference Video Generation},
author={Fang, Zhiyuan and others},
journal={arXiv},
year={2025}
}
ATI: Any Trajectory Instruction for Controllable Video GenerationAngtian Wang, Haibin Huang, Jacob Zhiyuan Fang, Yiding Yang, Chongyang Ma · arXiv 2025
Video GenerationMotion Controlled Video Generation
@inproceedings{yu2024zeroshot,
title={Zero-Shot Controllable Image-to-Video Animation via Motion Decomposition},
author={Yu, Shoubin and Fang, Jacob Zhiyuan and Zheng, Skyler and Sigurdsson, Gunnar A and Ordonez, Vicente and Piramuthu, Robinson and Bansal, Mohit},
booktitle={ACM Multimedia},
year={2024}
}
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image GenerationXuehai He, Jian Zheng, Jacob Zhiyuan Fang, Robinson Piramuthu, Mohit Bansal, Vicente Ordonez, Gunnar A. Sigurdsson, Nanyun Peng, Xin Eric Wang · TMLR 2024
@article{he2024flexecontrol,
title={FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author={He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
journal={TMLR},
year={2024}
}
Skews in the Phenomenon Space Hinder Generalization in Text-to-Image GenerationYingshan Chang, Yasi Zhang, Zhiyuan Fang, Yingnian Wu, Yonatan Bisk, Feng Gao · ECCV 2024
@inproceedings{chang2024skews,
title={Skews in the Phenomenon Space Hinder Generalization in Text-to-Image Generation},
author={Chang, Yuqing and Zhang, Yuchen and Fang, Zhiyuan and Wu, Yuchen and Bisk, Yonatan and Gao, Feng},
booktitle={ECCV},
year={2024}
}
SEED: Self-supervised Distillation For Visual RepresentationZhiyuan Fang, Jianfeng Wang, Lijuan Wang, Lei Zhang, Yezhou Yang, Zicheng Liu · ICLR 2021
@inproceedings{fang2021seed,
title={SEED: Self-supervised Distillation For Visual Representation},
author={Fang, Zhiyuan and Wang, Jianfeng and Wang, Lijuan and Zhang, Lei and Yang, Yezhou and Liu, Zicheng},
booktitle={ICLR},
year={2021}
}
Injecting Semantic Concepts into End-to-End Image CaptioningZhiyuan Fang, Jianfeng Wang, Xiaowei Hu, Lin Liang, Zhe Gan, Lijuan Wang, Yezhou Yang, Zicheng Liu · CVPR 2022
@inproceedings{fang2022injecting,
title={Injecting Semantic Concepts into End-to-End Image Captioning},
author={Fang, Zhiyuan and Wang, Jianfeng and Hu, Xiaowei and Liang, Lin and Gan, Zhe and Wang, Lijuan and Yang, Yezhou and Liu, Zicheng},
booktitle={CVPR},
year={2022}
}
Compressing Visual-linguistic Model via Knowledge DistillationZhiyuan Fang, Jianfeng Wang, Xiaowei Hu, Lijuan Wang, Yezhou Yang, Zicheng Liu · ICCV 2021
@inproceedings{fang2021compressing,
title={Compressing Visual-linguistic Model via Knowledge Distillation},
author={Fang, Zhiyuan and Wang, Jianfeng and Hu, Xiaowei and Lijuan Wang, Yezhou Yang, Zicheng Liu},
booktitle={ICCV},
year={2021}
}
ViTAA: Visual-Textual Attributes Alignment in Person Search by Natural LanguageZhe Wang, Zhiyuan Fang, Jun Wang, Yezhou Yang · ECCV 2020
@inproceedings{wang2020vitaa,
title={ViTAA: Visual-Textual Attributes Alignment in Person Search by Natural Language},
author={Wang, Zheng and Fang, Zhiyuan and Wang, Jianfeng and Yang, Yezhou},
booktitle={ECCV},
year={2020}
}